Yesterday is history, tomorrow is a mystery and today is a gift, that’s why they call it the present.
sqlserver数据库优化
一、数据库瓶颈-IO瓶颈
1.磁盘读IO瓶颈:
热点数据太多,数据库缓存放不下,每次查询会产生大量的IO,降低查询速度->分库和垂直分表
2.网络IO瓶颈:
请求的数据太多,网络带宽不够
二、数据库瓶颈-CPU瓶颈
1.SQL问题:
如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作->SQL优化,建立合适的索引,在业务Service层进行业务计算(不建议在数据库中对数据进行操作)。
2.单表数据量太大:
查询时扫描的行太多,SQL效率低,增加CPU运算的操作。
三、数据库压力过大
1.数据库性能降低,增加数据库服务延迟->Web服务器卡顿
2.数据库服务器宕机,造成数据库数据丢失,数据错乱,web服务瘫痪
常见的优化方案
1.加入索引—针对于查询
2.配置读写分离。让查询分摊出去。
【二八原则】一个主库:负责数据库中20%的写入-增删改 多个从库:应对80%的操作;共同负责查询动作
3.分库分表-化整为零操作数据库。
==高性能+高可用==
1.高性能–数据库服务响应快,加入索引,配置读写分离。让查询分摊出去。
2.高可用–保证数据库绝不会故障,数据库服务器一定不发生故障?做不到。如果要保证数据库无论如何都能够提供服务,只能采用==替补==模式。
SqlServer AlwaysOn高可用组
从SqlServer2012开始提供的一项数据库高可用解决方案。
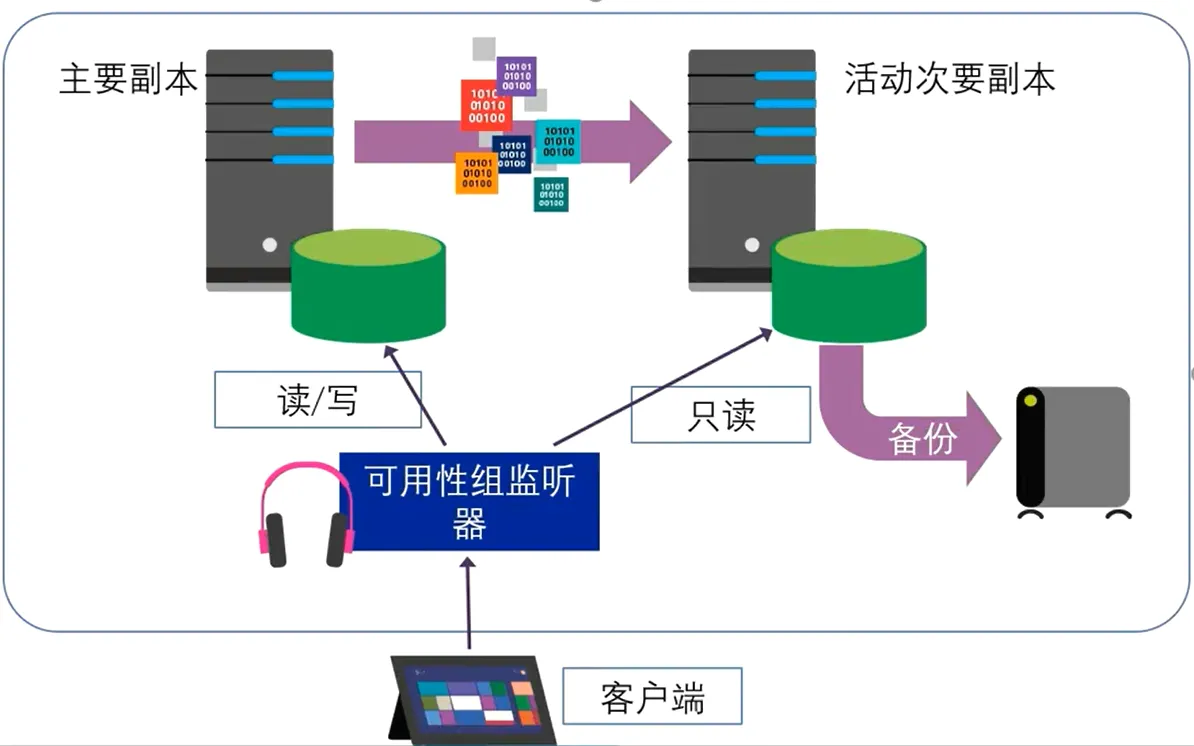
核心价值:
- 在Windows故障转移群集基础上完成部署
- 读写分离,支持负载均衡
- 2019最多可以有5个写入节点实现故障转移,5个数据实时同步节点
- SqlServer2012支持1+4部署
- SqlServer2016支持1+8部署
环境准备
基于Vmware搭建了四个windowsServer虚拟机
1.域控制DC主机 主机名:win-dc ip:192.168.1.120
2.SqlServer机-1 主机名:win-node01 ip:192.168.1.170
3.SqlServer机-2 主机名:win-node02 ip:192.168.1.180
4.SqlServer机-3 主机名:win-node03 ip:192.168.1.190
开始做域控
1.安装Activer Directory
通过【添加角色和功能】安装Activer Directory域服务和DNS服务器。
点击AD DS,然后点击进行配置,将此服务器提升为域控制器,然后根据Activer Directory域服务配置向导,添加新林,填写根域名,
2.安装DNS域名解析服务器
3.DC升级做域服务器
4.需要群集的节点加入域
系统属性,选择域,填写域名;使用固定ip地址,DNS服务器ip地址填域控制DC主机ip地址
最终结果:通过域账户登录,可以通过域名ping通
配置共享磁盘
1.windows故障转移群集,需要共享磁盘
安装iSCSI,【添加角色和功能】,勾选文件服务器
2.在DC机器配置网络磁盘
新建iSCSI虚拟磁盘,访问服务器 添加节点ip地址
3.需要故障转移群集的节点去联机共享磁盘
通过【工具】【iSCSI发起 程序】进行连接,然后可以初始化磁盘,新建卷
在节点服务器安装【故障转移群集】功能;添加网络适配器,其一是桥接模式,其二是仅主机模式;创建群集。
开始AlwaysOn高可用组
1.配置SqlServer登陆账号为域账号
2.开启AlwaysOn功能
SqlServer配置管理器中,sqlserver服务右键
3.开始新建AlwaysOn高可用组。
添加可用性组;可用性侦听器
4.测试
SqlServer性能优化
解决查询问题
- 把查询独立出去,就查询数据库的服务–让更多的服务器来支持
- 读写分离–分为主从数据库,一主多从
- 增删改汇聚到主数据库
- 主数据库同步数据到从库数据库
- 查询操作占数据库操作的80%,查询就可以让更多的服务器来支撑查询。更多的从数据库共同承载80%的查询行为;
矛盾:写入主库,查询从库,数据怎么能查询的到?
数据库的数据复制–价值
数据复制:多种–快照,数据库的日志;
特点:每个数据库中的数据包含的表中的数据都是完全一致的;
数据复制有延迟,延迟可以解决,不会太高。
读写分离四种模式
快照发布
发布服务器按预定的时间间隔向订阅服务器发送已发布数据的快照
特点:最低要延迟10s钟;数据的同步是批量性。同步表结构的变化;选定表范围内的变化,可以同步的;
对于一些数据库中增删改相对频繁的操作可以考虑快照;
事务发布–最推荐-延迟最小
在订阅服务器收到已发布数据的初始快照后,发布服务器将事务流式传输到订阅服务器。
适用于增删改少-查询多的情况
特点:表必须有主键;发布方修改表结构,表结构不能同步;只能同步数据库;增加表,也是不能同步的。
延迟比较低,事务流,及时性高。
对等发布
对等发布支持多主复制。发布服务器将事务流式传输到拓扑中的所有对等方。所有对等节点可以读取和写入更改,且所有更改将传播到拓扑中的所有节点。
合并发布
在订阅服务器收到已发布数据的初始快照后,发布服务器和订阅服务器可以独立更新已发布数据。更改会定期合并。Microsoft SQL Server Compact Edition只能订阅合并发布。
1.发布服务器:主要节点-主数据库
2.分发服务器:配置数据需要复制的,数据要复制的文件保存到分发服务器
3.订阅服务器:从数据库
什么是索引
索引是对数据表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。让我们在做数据查询的过程中,提升查询的效率。
索引的合理使用
1.添加索引的时候,数据库引擎需要合成索引,在合成的过程中,需要有大量的数据指向的调整;
2.索引的生成——会影响增加删改的性能,尤其是增加数据和删除数据之后、增加、删除后。重新维护新的数据库的索引结构;
性能指标:响应时间,吞吐量,可扩展性
平衡:
最小化每个sql的响应时间
合理增加吞吐量
减少网络延时
优化磁盘IO、CPU
能够协调、平衡的运作->合理的响应外部的请求->实现资源利用最大化
常见因素的影响:
数据库结构的设计
性能优化->贯穿整个生命周期
了解业务->系统为了满足业务需求
优先考虑第三范式设计:字段冗余->避免多表关联的手段
查询->默认加载查询->10万次
更新->每天甚至几天才会更新一次
表关联尽可能少,使用简单的sql语句,避免过多的表关联
坚持最小原则:尽可能的字段类型
适当的使用约束:安全方面
sql语句的编写
数据文件的位置
TempDB系统库->全局资源->放在独立的磁盘、减少分配争用
Model系统–Raid 0
数据拆分–>与CPU物理线程个数相同
用户系统库和日志文件隔离存放
数据文件->随机读写
日志文件->顺序读写
主文件组仅供系统使用
硬件资源
扫描运算符:表扫描->堆表、聚集索引扫描、非聚集索引扫描(包含在定义好的索引中,索引中已经包含数据,覆盖索引)
扫描->性能的最大杀手
缓存数据会频繁交替->性能瓶颈
查找运算符->索引
通过索引去定位数据
聚集索引查找
非聚集索引查找->非聚集索引字段进行where过滤
键查找->标签查找(使用了非聚集索引的语句中,用于查找不包含在当前索引中的字段)
Order by->参与排序操作的数据量的大小
避免对大批数据进行排序操作
中间数据->TempDB数据库->存储查询过程中产生的中间数据
排序过程->工作区内存->TempDB数据库->IO的开销
Group by + distinct
where 子句
是否有合适的索引
字段上是否存在函数计算
结果集是否过大
是否仅查询出需要的字段
合理索引的选择->查找的方式->去查询某个或若干个覆盖索引
覆盖索引-包含了当前查询语句所使用的左右字段信息
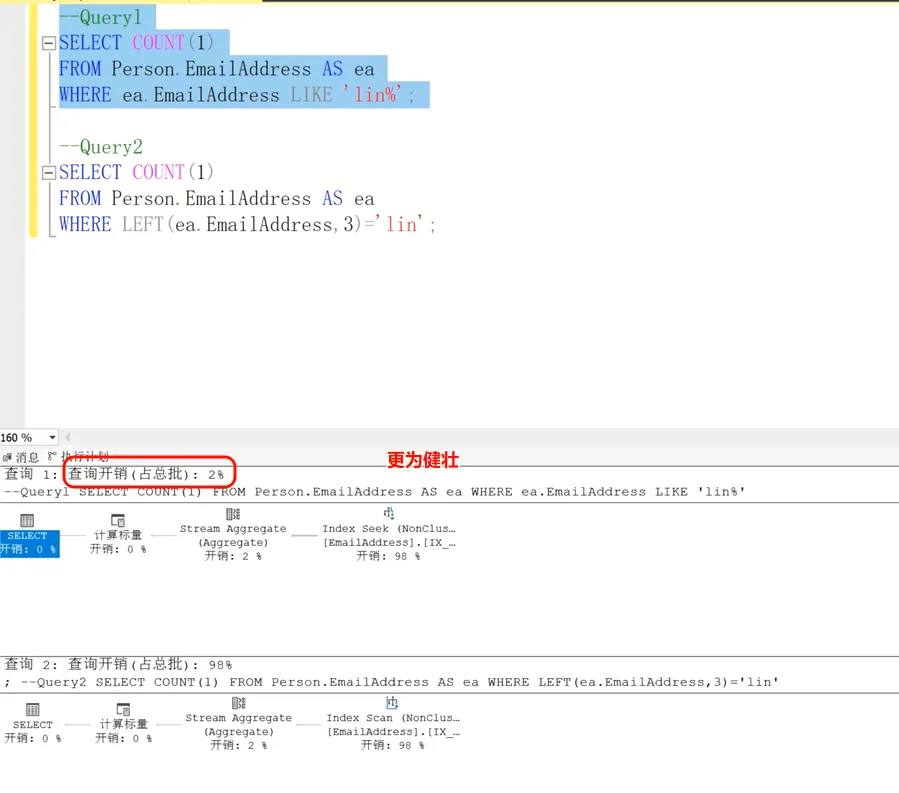
SARG->可以高效使用索引的写法
非SARG
where条件符号左边出现标量函数
where upper(列名) = ‘A’ – > where (列名 = ‘A’ or 列名 = ‘a’)
where 列-1 = 某个值 —>where 列 = 某个值 + 1
left(Column,3) = ‘ABC’ — >Column like ‘ABC%’
DATEADD(day,7,列名) > GETDATE() — 》 列名 > DATEADD(day,-7,GETDATE())
隐式类型转换
子查询 - > 嵌套在查询语句里的查询语句 - > 出现在where 子句、Select 语句某个字段的表达式
尽量出现在where子句
子查询的数量不超过3个,整个涉及的表不超过5个
子查询–>常用的连接操作
无法转化的情况–>优先执行–>结果集作为下一个操作的输入部分
避免在子查询中对大数据集进行汇总或排序操作
尽量缩小子查询中可能返回的结果集
尽量使用确定性的判断符、=、in、exists,避免使用any、some、all
In exists –》inner join

