Kubernetes核心技术Pod
Pod概述
Pod 是 Kubernetes 中最小的部署和调度单元,是一组共享网络和存储资源的容器集合。
Pod基本概念
1.Pod 是 Kubernetes 中最小的部署和调度单位
Kubernetes 不会直接创建或管理单个容器,而是以 Pod 为单位进行调度和运行。也就是说,当你部署应用时,实际创建的是 Pod,而不是容器。
2.一个 Pod 可以包含一个或多个容器
一个 Pod 本质上是一个容器组,这些容器通常是紧密相关的,比如主业务容器 + 日志收集容器或代理容器。但在实际生产中,大多数 Pod 只包含一个容器,多容器更多用于特定场景(如 sidecar 模式)。
3.同一个 Pod 内的容器共享网络环境
Pod 内所有容器共享同一个 IP 地址和端口空间,因此它们之间可以通过 127.0.0.1 直接通信,就像在同一台机器上一样,不需要额外的服务发现机制。
4.同一个 Pod 内的容器可以共享存储
通过 Volume,可以让 Pod 内多个容器访问同一份数据,实现文件共享,例如一个容器写日志,另一个容器读取并上传日志。
5.Pod 中所有容器的生命周期是绑定的
Pod 被创建时,里面的容器一起启动;Pod 被删除时,所有容器一起销毁。它们不能独立存在,始终作为一个整体运行。
6.Pod 是短生命周期资源,而不是稳定实体
Pod 可能因为调度、扩缩容或故障而被销毁并重新创建,因此 Pod 的 IP 和实例并不稳定,不能依赖它作为长期标识。
7.每个 Pod 都有一个隐式的基础容器(Pause)
这个容器负责维持 Pod 的网络命名空间,其他业务容器共享它的网络环境,从而实现“同一个 Pod 共享 IP”的能力。
Pod存在的意义
1.解决容器之间协作困难的问题
单个容器之间默认是隔离的,通信和数据共享都比较复杂。Pod 提供了共享网络和存储的能力,使多个容器可以像在同一台机器上一样高效协作。
2.提供统一的调度和管理单位
如果直接调度容器,调度粒度会过细,也无法保证多个相关容器被同时调度到同一节点。Pod 将多个容器打包成一个整体,使 Kubernetes 可以以更合理的粒度进行调度和管理。
3.保证多个容器“必须一起运行”
有些场景中,多个容器是强依赖关系,例如主应用必须依赖一个代理或日志组件。Pod 能保证这些容器始终一起创建、一起运行、一起销毁,不会被拆散。
4.支持 Sidecar 等架构模式
Pod 让你可以在不修改主应用的情况下,通过附加容器实现日志收集、流量代理、安全控制等功能,从而增强系统能力。
5.屏蔽底层容器差异,提供统一抽象
Kubernetes 不直接操作 Docker 或其他容器运行时,而是通过 Pod 这一层抽象来统一管理不同类型的容器运行环境。
6.为上层控制器提供管理基础
Deployment、StatefulSet 等控制器并不直接管理容器,而是管理 Pod。Pod 是整个 Kubernetes 控制体系中最基础的执行单元。
Pod实现机制
主要有以下两大机制
- 共享网络
- 共享存储
共享网络
背景
容器默认是相互隔离的,这种隔离主要通过 Linux 的 Namespace(命名空间) 实现,其中网络隔离由 Network Namespace 提供。
核心问题
在默认情况下:
- 每个容器都有独立的网络空间
- 容器之间不能直接通过
127.0.0.1通信
👉 那么:
Pod 内多个容器如何实现高效通信?
核心机制
Kubernetes 通过 共享 Network Namespace 来实现 Pod 内容器通信。
实现原理
当 Pod 创建时,Kubernetes 会先创建一个特殊容器:Pause 容器(作用是持有 Pod 的 Network Namespace(网络命名空间)),然后创建业务容器,例如:nginx/redis等,同时,将业务容器加入 Pause 容器的 Network Namespace。
特点总结:
- Pod 内所有容器共享一个 IP
- 容器之间可以通过 localhost 通信
- 不需要额外网络组件(如 Service)
共享存储
背景
容器默认是隔离的:
- 每个容器有独立的文件系统
- 容器之间无法直接共享数据
问题:
同一个 Pod 内多个容器如何共享数据?
核心解决方案
Kubernetes 通过 Volume(存储卷)机制 实现 Pod 内数据共享
实现原理
1.在 Pod 中定义 Volume
| |
2.容器挂载 Volume
| |
3.最终结构
| |
4.常见 Volume 类型
emptyDir(最常用 ⭐)
1emptyDir: {}特点:
- Pod 创建时生成
- Pod 删除时数据清空
- 存储在 Node 本地
hostPath(宿主机目录)
1 2hostPath: path: /data特点:
- 直接使用 Node 上的目录
- 不安全(生产慎用)
PVC(生产主流 ⭐⭐⭐)
1PVC → PV → 存储系统特点:
- 数据持久化
- Pod 删除数据不丢
- 可跨 Pod 使用
==注意:==
- emptyDir 是临时存储
- Volume 不是全局共享
- 不同 Pod 共享需要持久化存储
Pod镜像拉取策略
我们以具体实例来说,拉取策略就是 imagePullPolicy

拉取策略主要分为了以下几种
- IfNotPresent:默认值,本地有镜像->直接使用;反之,从仓库拉取
- Always:每次创建Pod都会重新拉取一次镜像
- Never:只使用本地镜像,不会拉取
==默认策略规则==
不写 imagePullPolicy:Kubernetes 自动判断规则:
情况1:镜像带 :latest 默认:Always
情况2:镜像带具体版本 默认 IfNotPresent
情况3:不写 tag 等价于: 情况1
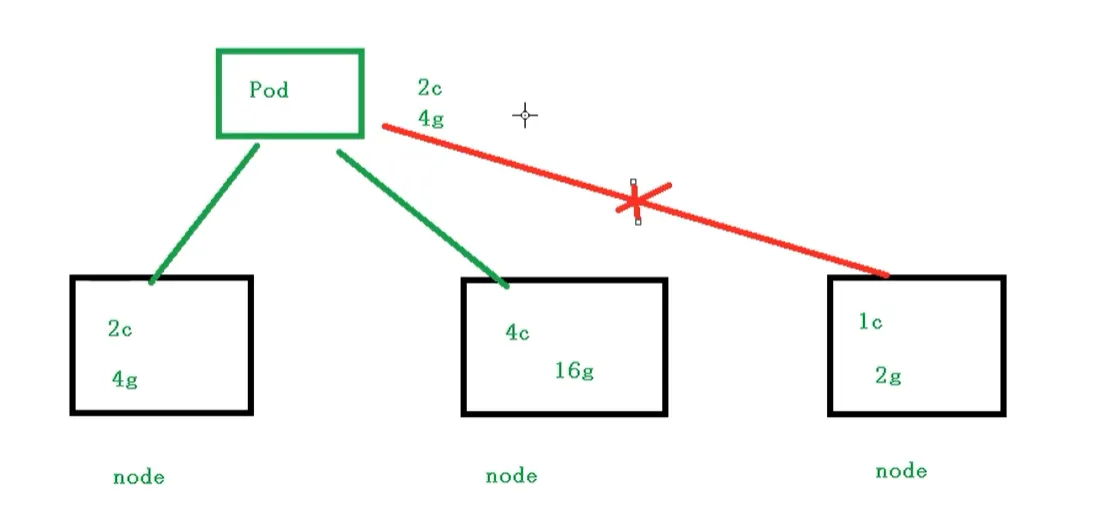
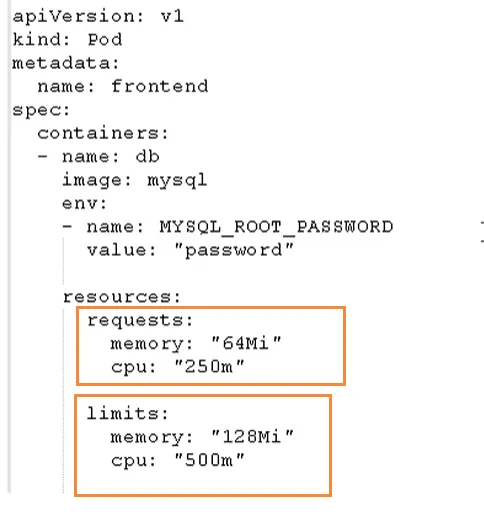
Pod资源限制
概述:
Kubernetes 通过
requests和limits来描述 Pod 对资源的需求和上限,从而实现资源调度和运行时控制。资源主要包括:
- CPU
- 内存(Memory)
1.requests(请求资源)
调度时的“最低保障资源”
| |
作用:Scheduler 根据 requests 选择 Node
2.limits(资源上限)
容器运行时最多能使用的资源
| |
作用:由 kubelet + 容器运行时 强制限制
调度 vs 运行
| 阶段 | 作用 |
|---|---|
| 调度阶段 | 使用 requests |
| 运行阶段 | 使用 limits |
CPU 和 内存的区别
CPU可以“压缩”(throttle),超过 limit:不会杀掉容器,只是限速
内存不能压缩,超过 limit:直接 OOMKilled(容器被杀)
示例
| |
含义:
- 最少需要 0.5 核 CPU
- 最多使用 1 核
- 最少 512MB 内存
- 最大 1GB 内存
调度过程
| |
常见问题
问题1:Pod 一直 Pending
| |
问题2:容器频繁重启(OOMKilled)
| |
问题3:CPU 使用很慢
| |
Pod重启机制
Kubernetes 通过
restartPolicy控制 Pod 内容器在退出后的重启行为注意:控制的是“容器重启”,不是 Pod 重启
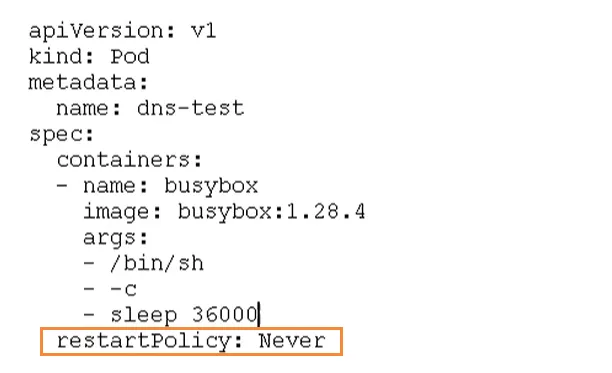
重启策略主要分为以下三种
- Always:无论容器正常退出还是异常退出,都会重启,默认策略 【nginx等,需要不断提供服务】
- OnFailure:只有退出码 ≠ 0(异常退出)才重启【任务型应用(如批处理)】
- Never:无论成功还是失败,都不会重启【一次性任务 / 调试】
不同控制器的默认策略
| 控制器 | restartPolicy |
|---|---|
| Deployment / ReplicaSet | Always |
| StatefulSet | Always |
| DaemonSet | Always |
| Job | OnFailure / Never |
注意事项
restartPolicy 作用范围——>只对 Pod 生效
Pod 不会“原地重启”——>重建,而不是重启
CrashLoopBackOff 不是策略——>是状态,不是配置
Pod健康检查
通过容器检查,原来我们使用下面的命令来检查
| |
但是有的时候,程序可能出现了 Java 堆内存溢出,程序还在运行,但是不能对外提供服务了,这个时候就不能通过 容器检查来判断服务是否可用了
典型情况包括:
- JVM 堆内存溢出(OOM)
- 线程死锁 / 卡死
- GC 频繁导致假死
- 数据库连接池耗尽
- 依赖服务挂了(Redis/MySQL)
这个时候就可以使用应用层面的检查
三种 Probe 的核心区别
| 类型 | 作用 | 失败后行为 | 典型用途 |
|---|---|---|---|
| livenessProbe | 进程是否“活着” | 重启 Pod | 卡死 / 死循环 |
| readinessProbe | 是否“可以接流量” | 从 Service 移除 | 启动慢 / 依赖不可用 |
| startupProbe | 是否“启动完成” | 失败才触发其他 probe | Java 启动慢 / 大应用 |
livenessProbe(存活探针)
判断:这个容器还能不能活下去
失败后:
- Kubernetes 直接杀 Pod
- 按 restartPolicy 重启
典型场景
- Java OOM 但进程没退出
- 死循环
- 线程完全卡死
示例(HTTP方式)
| |
readinessProbe(就绪探针)
👉 判断:服务能不能接流量
失败后:
- Pod 不会被杀
- 只是从 Service endpoints 中移除
典型场景
- 应用刚启动(还在加载配置)
- 依赖 MySQL / Redis 未连接成功
- 线程池未初始化完成
示例
| |
startupProbe(启动探针|非常重要但常被忽略)
👉 专门解决:
“应用启动太慢导致 livenessProbe 误杀”
场景(Java 很常见)
- Spring Boot 启动 60s+
- 大型微服务初始化缓存
- JVM warm-up
行为:
- 在 startupProbe 成功前
- liveness/readiness 都不会执行
示例
| |
👉 等于:最多允许 300 秒启动时间

Probe支持以下三种检查方式
- http Get:发送HTTP请求,返回200 - 399 范围状态码为成功,400/500 失败
- exec:执行Shell命令返回状态码是0为成功
- tcpSocket:发起TCP Socket建立成功
Pod调度策略
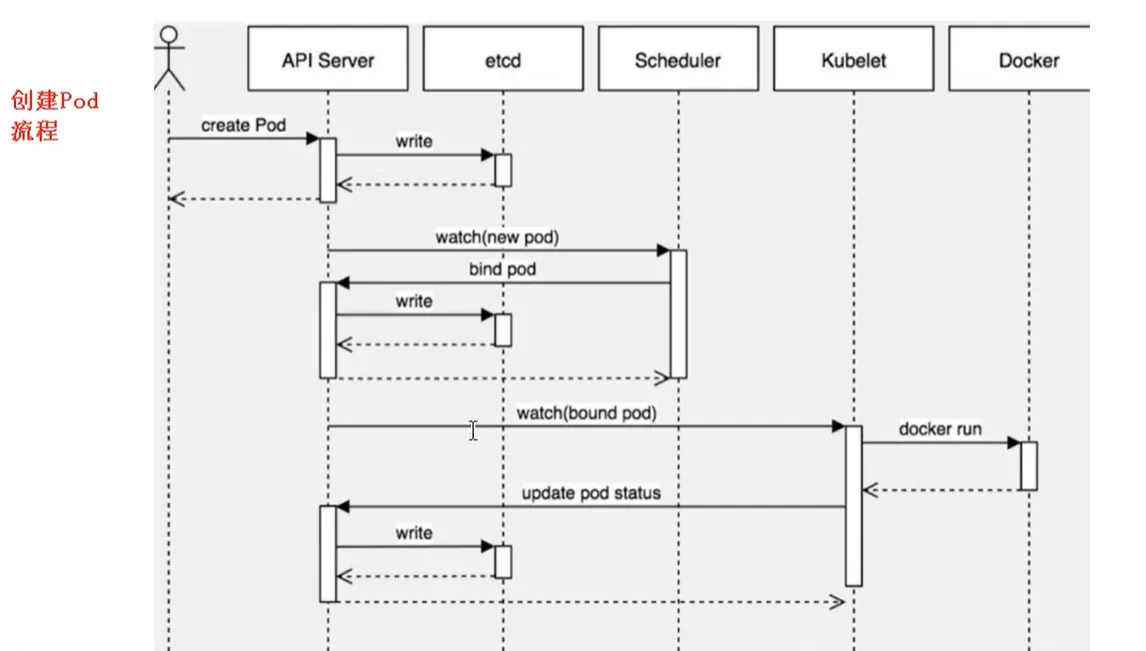
创建Pod流程
- 用户提交 Pod 请求,kubectl → API Server
- API Server 处理请求 (认证,鉴权,校验)然后把 Pod 写入 etcd(持久化存储) API Server → Etcd
- Scheduler 通过 watch API Server 发现有 Pod = Pending(未绑定 Node),然后做调度算法,选择一个 Node,并更新API Server → Pod.spec.nodeName = node1
- 资源(CPU / Memory)
- Node 是否有污点(Taint)
- Affinity / Anti-Affinity
- Pod 优先级
- 负载均衡
- kubelet 监听 Pod (每个 Node 上都有 kubelet,也是 watch API Server)发现这个Pod 被分配到我这个 Node
- kubelet 调用 Container Runtime kubelet 不直接操作 Docker,而是:kubelet → CRI → containerd / CRI-O
- 流程:
- 拉取镜像
- 创建容器
- 启动容器
- 挂载 Volume
- 设置网络(CNI)
- 网络 & 存储初始化 由CNI(Calico / Flannel)/CSI(存储插件)插件完成
- Pod 状态回写 kubelet 会把状态更新回:kubelet → API Server → etcd
- 状态变更:
- Pending
- Running
- Failed
- Succeeded
| |
| |
影响 Pod 调度的三大核心因素
Pod资源限制对Pod的调度会有影响
Resource Request / Limit(最基础)
作用机制
Scheduler 只看:
Node 是否 “剩余可分配资源 ≥ request”
👉 注意:
- request = 调度依据(硬条件)
- limit = 运行上限(不是调度依据)
NodeSelector(最简单的标签约束)
关于节点选择器,其实就是有两个环境,然后环境之间所用的资源配置不同
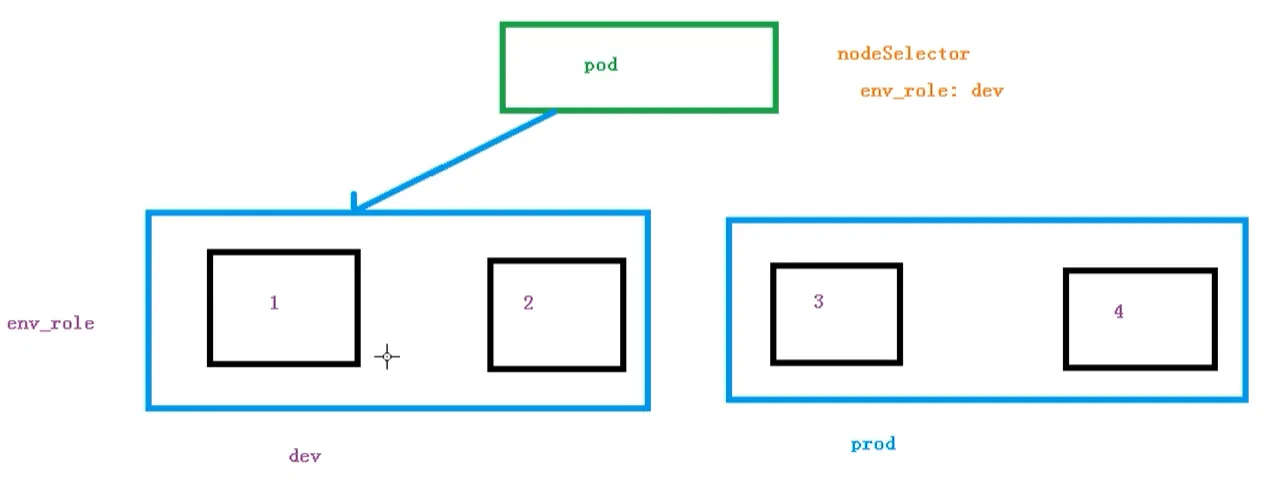
我们可以通过以下命令,给我们的节点新增标签,然后节点选择器就会进行调度了
| |
Node Affinity
节点亲和性 nodeAffinity 和 之前nodeSelector 基本一样的,根据节点上标签约束来决定Pod调度到哪些节点上
- 硬亲和性:约束条件必须满足
- 软亲和性:尝试满足,不保证

支持常用操作符:
| 操作符 | 含义 |
|---|---|
| In | 包含 |
| NotIn | 不包含 |
| Exists | 存在 key |
| DoesNotExist | 不存在 key |
| Gt / Lt | 数值比较 |
Anti-Affinity(反亲和性)
常见用途:
- 多副本 Pod 不要落在同一节点
- 高可用部署(HA)
| |
就是和亲和性刚刚相反,如 NotIn、DoesNotExists等
污点和污点容忍
概述
nodeSelector 和 NodeAffinity,都是Prod调度到某些节点上,属于Pod的属性,是在调度的时候实现的。
Taint 污点:节点不做普通分配调度,是节点属性
场景
- 专用节点【限制ip】
- 配置特定硬件的节点【固态硬盘】
- 基于Taint驱逐【在node1不放,在node2放】
查看污点情况
| |
三种 effect:
| 类型 | 含义 | 行为 |
|---|---|---|
| NoSchedule | 不允许调度 | 新 Pod 不能进 |
| PreferNoSchedule | 尽量不调度 | 可能还是会进 |
| NoExecute | 驱逐 + 不允许调度 | 已有 Pod 也会被踢 |
未节点添加污点
| |
举例:
| |
删除污点
| |

演示
我们现在创建多个Pod,查看最后分配到Node上的情况
首先我们创建一个 nginx 的pod
| |
然后使用命令查看
| |

我们可以非常明显的看到,这个Pod已经被分配到 k8snode1 节点上了
下面我们把pod复制5份,在查看情况pod情况
| |
我们可以发现,因为master节点存在污点的情况,所以节点都被分配到了 node1 和 node2节点上

我们可以使用下面命令,把刚刚我们创建的pod都删除
| |
现在给了更好的演示污点的用法,我们现在给 node1节点打上污点
| |
然后我们查看污点是否成功添加
| |

然后我们在创建一个 pod
| |
然后我们在进行查看
| |
我们能够看到现在所有的pod都被分配到了 k8snode2上,因为刚刚我们给node1节点设置了污点

最后我们可以删除刚刚添加的污点
| |
污点容忍
Toleration(容忍)不是决定“能不能调度”,而是允许 Pod “无视污点限制”
核心关系是:
- Taint:节点拒绝什么 Pod
- Toleration:Pod 能不能“忍受”这个拒绝

Toleration
1.Pod 如何“突破污点限制”
| |
这个 Pod 可以“容忍” node1 的 NoSchedule 污点
Taint vs NodeAffinity
| 项目 | Taint/Toleration | NodeAffinity |
|---|---|---|
| 作用对象 | Node → Pod 拒绝 | Pod → Node 选择 |
| 控制方向 | 反向控制 | 正向选择 |
| 是否强制 | 可以强制驱逐 | 只是调度约束 |
| 本质 | “不让你来” | “我要去哪里” |
K8s 调度系统全景图(Affinity + Taint + Scheduler + Controller)

文字说明:
这张“K8s 调度系统全景图”本质上是在讲 Kubernetes 从用户提交 Pod 到最终在某个 Node 上运行的完整链路,它不是一个线性流程,而是一个由“控制平面决策 + 节点执行 + 多种约束过滤 + 控制器持续纠偏”共同组成的闭环系统。
当用户通过 kubectl 提交一个 Pod YAML 时,本质上只是向 API Server 提交了一个“期望状态声明”,比如希望运行一个 nginx、需要多少 CPU 和内存、是否有节点亲和性要求、是否允许容忍某些污点节点等。API Server 是整个系统的入口,它首先会对请求进行认证(Authentication)、授权(Authorization)、以及 Admission Controller 的准入校验,确保这个 Pod 的定义是合法且符合集群策略的。通过校验后,Pod 对象会被写入 etcd 中进行持久化存储。etcd 在 Kubernetes 中承担的是“唯一事实源”的角色,所有组件都以它为准,而不是直接相互通信。
接下来进入调度阶段,Scheduler 会通过 watch 机制监听 API Server 中是否存在未绑定 Node 的 Pod(Pending 状态)。一旦发现新的 Pod,它不会直接随机分配,而是进入一个非常标准的调度流程。这个流程可以理解为三步:过滤(Filter)、打分(Score)、绑定(Bind)。
在 Filter 阶段,Scheduler 会先排除掉所有不符合条件的节点。这里的条件包括多个维度:第一是资源维度,也就是 Pod 的 resource requests,Scheduler 会检查 Node 上是否还有足够 CPU 和内存可分配,如果不够直接淘汰;第二是节点选择约束,包括 nodeSelector 和 nodeAffinity,如果 Pod 明确要求只能运行在某些标签的节点上,那么不满足标签的节点会被过滤掉;第三是污点机制 Taint,如果节点设置了 NoSchedule 类型的污点,而 Pod 又没有对应的 toleration,那么该节点也会被直接排除。这一步本质是在做“可行性筛选”。
当候选节点缩小之后,Scheduler 进入 Score 阶段,对每个可用节点进行打分。评分依据包括资源使用均衡性、Pod 分布均匀性、亲和性优先级、拓扑分布约束等。例如 Kubernetes 会尽量避免某个节点过载,也会尽量让同一应用的多个副本分散在不同节点上,提高高可用能力。nodeAffinity 中的 preferred 规则也会在这一阶段影响权重,从而影响最终选择结果。
在 Score 完成之后,Scheduler 会选择得分最高的节点,并执行 Bind 操作,将 Pod 与该节点绑定,本质上是更新 Pod.spec.nodeName 字段,并写回 API Server 和 etcd。至此,调度决策完成,但 Pod 还没有真正运行。
真正执行发生在 Node 节点上。每个 Node 上运行着 kubelet,它是节点上的“执行代理”。kubelet 同样通过 watch API Server 获取分配到本节点的 Pod,一旦发现 Pod.spec.nodeName 匹配当前节点,它就开始执行创建流程。需要特别注意的是 kubelet 并不会直接访问 etcd,也不会直接和 Scheduler 通信,它只和 API Server 交互,这是很多人容易误解的点。
kubelet 接下来会调用 CRI(Container Runtime Interface),比如 containerd 或 CRI-O 来真正创建容器。这个过程中包括拉取镜像、创建容器、挂载存储(CSI)、以及网络初始化(CNI)。最终 Pod 内的容器被启动,进入 Running 状态,同时 kubelet 会持续将 Pod 状态回写到 API Server,用于状态同步。
在整个过程中,Affinity 和 Taint/Toleration 扮演的是“约束系统”。Node Affinity 是 Pod 主动选择节点的机制,它决定 Pod 想去哪里,可以是强制(required)或偏好(preferred);而 Taint 是节点主动设置的“拒绝规则”,表示这个节点不接受某些类型的 Pod;Toleration 则是 Pod 的“通行证”,决定它是否可以进入被污点限制的节点。两者方向是相反的:Affinity 是“我想去哪里”,Taint 是“你不能来”,Toleration 是“但我可以例外进入”。
最后还有一个非常关键但经常被忽略的部分,就是 Controller 控制器体系。Kubernetes 并不是一次性调度完成就结束,而是一个持续的“自愈系统”。例如 Deployment Controller 会不断检查副本数是否满足,如果 Pod 挂了会重新创建;NodeController 会监控节点健康状态,如果节点 NotReady 会触发 Pod 驱逐;TaintController 可以自动给异常节点打污点,从而阻止新的 Pod 调度进去。整个系统本质是一个持续运行的控制循环(Control Loop),不断对比“期望状态”和“实际状态”,并自动修正偏差。
综合来看,这张图表达的核心思想是:Kubernetes 调度不是简单的“选机器运行容器”,而是一个多层约束过滤 + 打分决策 + 节点执行 + 控制器自愈的闭环系统。Scheduler 决定“放哪”,Affinity 决定“想去哪”,Taint 决定“能不能来”,Controller 决定“是否需要修正”。整个体系共同保证了集群在复杂环境下依然能够稳定运行。

