[TOC]
一、alertmanager#
1.1 alertmanager介绍#
监控告警实现需要依赖 Alertmanager。
1.2 源码方式安装启动#
1. 文件准备#
将下载好的Alertmanager文件解压
输入
1
| tar -zxvf alertmanager-0.21.0.linux-386.tar.gz
|
然后移动到/opt/prometheus文件夹里面,没有该文件夹则创建
2. alertmanager启动#
root用户下启动
输入:
1
| nohup ./alertmanager >/dev/null 2>&1 &
|
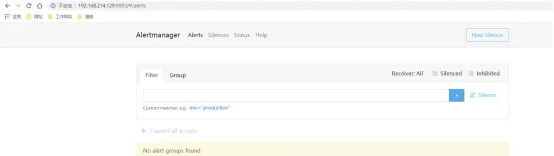
启动成功之后,在浏览器上输入 ip+9093可以查看相关信息
示例图:
1.3 docker方式安装启动#
1
| docker run -d --name alertmanager -p 9093:9093 -v /home/prometheus/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager:latest
|
1.4 alertmanager邮箱告警配置#
1. 告警文件alertmanager.yml的配置#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| global:
resolve_timeout: 5m
# 所有报警信息进入后的根路由,用来设置报警的分发策略
smtp_from: '1090239782@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1090239782@qq.com'
smtp_auth_password: 'dmsitabajsjbhbda'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
#当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: 'email' # 优先使用default发送
receivers:
- name: 'email'
email_configs:
- to: '1090239782@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
|
注: smtp_from、smtp_auth_username、to的邮箱可以填写同一个,smtp_auth_password填写鉴权码,需要开启POS3。
1.5 添加告警模板#
在alertmanagers的文件夹下创建一个template文件夹,然后在该文件夹创建一个微信告警的模板wechat.tmpl,添加如下配置:
1
2
3
4
5
6
7
8
9
10
11
12
| {{ define "wechat.default.message" }}
{{ range .Alerts }}
========start=========
告警程序: prometheus_alert
告警级别: {{ .Labels.severity}}
告警类型: {{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
=========end===========
{{ end }}
{{ end }}
|
然后再到alertmanager.yml 添加如下配置:
1
2
| templates:
- '/opt/prometheus/alertmanager-0.21.0.linux-386/template/wechat.tmpl'
|
效果图:

1.6 内存告警设置#
1
2
3
4
5
6
7
8
9
10
11
| - name: test-rule
rules:
- alert: "内存报警"
expr: 100 - ((node_memory_MemAvailable_bytes * 100) / node_memory_MemTotal_bytes) > 30
for: 15s
labels:
severity: warning
annotations:
summary: "服务名:{{$labels.instance}}内存使用率超过30%了"
description: "业务500报警: {{ $value }}"
value: "{{ $value }}"
|
1.7 磁盘告警配置#
1. 总量百分比设置:#
1
| (node_filesystem_size_bytes {mountpoint ="/"} - node_filesystem_free_bytes {mountpoint ="/"}) / node_filesystem_size_bytes {mountpoint ="/"} * 100
|
2. 查看某一目录的磁盘使用百分比#
1
| (node_filesystem_size_bytes{mountpoint="/boot"}-node_filesystem_free_bytes{mountpoint="/boot"})/node_filesystem_size_bytes{mountpoint="/boot"} * 100
|
3. 正则表达式来匹配多个挂载点#
(node_filesystem_size_bytes{mountpoint="/|/run"}-node_filesystem_free_bytes{mountpoint="/|/run"})
/ node_filesystem_size_bytes{mountpoint=~"/|/run"} * 100
4. 预计多长时间磁盘爆满#
predict_linear(node_filesystem_free_bytes {mountpoint ="/"}[1h],
43600) < 0 predict_linear(node_filesystem_free_bytes
{job=“node”}[1h], 43600) < 0
1.8 CPU使用率#
100 - (avg(irate(node_cpu_seconds_total{mode=“idle”}[5m])) by
(instance) * 100)
1.9 空闲内存剩余率#
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)
/ node_memory_MemTotal_bytes * 100
1.10 内存使用率#
100 -
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)
/ node_memory_MemTotal_bytes * 100
1.11 磁盘使用率#
100 - (node_filesystem_free_bytes{mountpoint="/",fstype=“ext4|xfs”} /
node_filesystem_size_bytes{mountpoint="/",fstype=“ext4|xfs”} * 100)
二、webhook#
1
| docker run -d -p 8060:8060 --name webhook timonwong/prometheus-webhook-dingtalk --ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=钉钉token"
|
三、prometheus#
prometheus-config.yml
1
2
3
4
5
6
7
8
9
| alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.0.50:9093
rule_files:
- "/home/prometheus/rules/node_down.yml" # 实例存活报警规则文件
- "/home/prometheus/rules/memory_over.yml" # 内存报警规则文件
- "/home/prometheus/rules/cpu_over.yml" # cpu报警规则文件
|

