初识Shell
一、程序
1、什么是程序
程序是为实现特定目标或解决特定问题而用计算机语言编写的命令序列的集合。
二、语言
有哪些编程语言?
编程语言总体分以为机器语言、汇编语言、高级语言
1、机器语言
- 由于计算机内部只能接受二进制代码,因此,用二进制代码0和1描述的指令称为机器指令,全部机器指令的集合构成计算机的机器语言,用机器语言编程的程序称为目标程序。只有目标程序才能被计算机直接识别和执行。但是机器语言编写的程序无明显特征,难以记忆,不便阅读和书写,且依赖于具体机种,局限性很 大,机器语言属于低级语言。
- 用机器语言编写程序,编程人员要首先熟记所用计算机的全部指令代码和代码的涵义。手编程序时,程序员得自己处理每条指令和每一数据的存储分配和输入输出,还得记住编程过程中每步所使用的工作单元处在何种状态。这是一件十分繁琐的工作。编写程序花费的时间往往是实际运行时间的几十倍或几百倍。而且,编出的程序全是些0和1的指令代码,直观性差,还容易出错。除了计算机生产厂家的专业人员外,绝大多数的程序员已经不再去学习机器语言了。机器语言是微处理器理解和使用的,用于控制它的操作二进制代码。
2、汇编语言
- 汇编语言的实质和机器语言是相同的,都是直接对硬件操作,只不过指令采用了英文缩写的标识符,更容易识别和记忆。它同样需要编程者将每一步具体的操作用命令的形式写出来。
- 汇编程序的每一句指令只能对应实际操作过程中的一个很细微的动作。例如移动、自增,因此汇编源程序一般比较冗长、复杂、容易出错,而且使用汇编语言编程需要有更多的计算机专业知识,但汇编语言的优点也是显而易见的,用汇编语言所能完成的操作不是一般高级语言所能够实现的,而且源程序经汇编生成的可执行文件不仅比较小,而且执行速度很快。
3、高级语言
- 高级语言是大多数编程者的选择。和汇编语言相比,它不但将许多相关的机器指令合成为单条指令,并且去掉了与具体操作有关但与完成工作无关的细节,例如使用堆栈、寄存器等,这样就大大简化了程序中的指令。同时,由于省略了很多细节,编程者也就不需要有太多的专业知识。
- 高级语言主要是相对于汇编语言而言,它并不是特指某一种具体的语言,而是包括了很多编程语言,像最简单的编程语言PASCAL语言也属于高级语言。
- 高级语言所编制的程序不能直接被计算机识别,必须经过转换才能被执行,按转换方式可将它们分为两类:
- 编译类 编译是指在应用源程序执行之前,就将程序源代码“翻译”成目标代码(机器语言),因此其目标程序可以脱离其语言环境独立执行(编译后生成的可执行文件,是cpu可以理解的2进制的机器码组成的),使用比较方便、效率较高。但应用程序一旦需要修改,必须先修改源代码,再重新编译生成新的目标文件(*.obj,也就是OBJ文件)才能执行,只有目标文件而没有源代码,修改很不方便。编译后程序运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++、Delphi等
- 解释类 执行方式类似于我们日常生活中的“同声翻译”,应用程序源代码一边由相应语言的解释器“翻译”成目标代码(机器语言),一边执行,因此效率比较低,而且不能生成可独立执行的可执行文件,应用程序不能脱离其解释器(想运行,必须先装上解释器,就像跟老外说话,必须有翻译在场),但这种方式比较灵活,可以动态地调整、修改应用程序。如Shell,Python、Java、PHP、Ruby等语言。
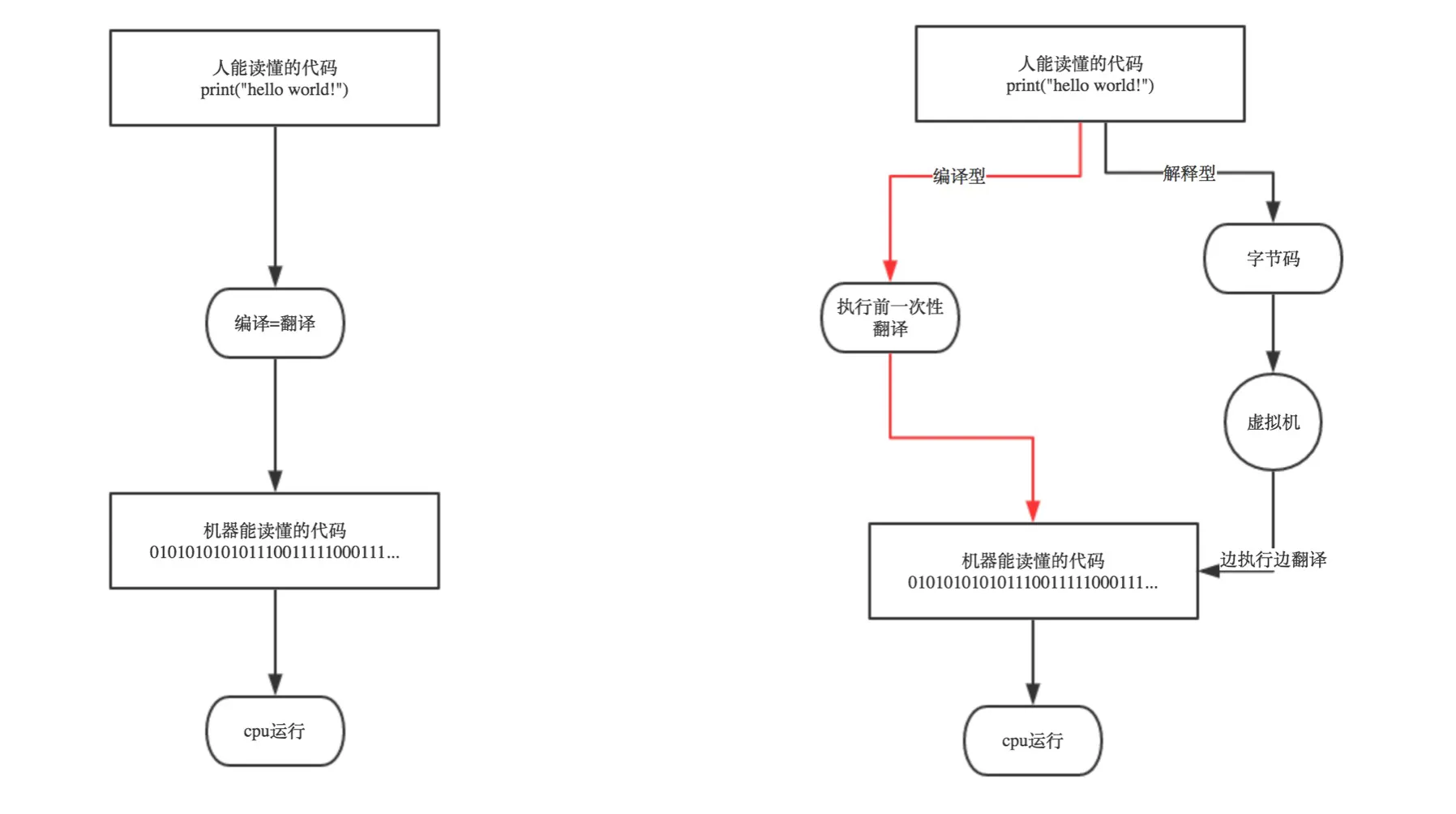
4、总结
1、机器语言
- 优点是最底层,速度最快,缺点是最复杂,开发效率最低
2、汇编语言
- 优点是比较底层,速度最快,缺点是复杂,开发效率最低
3、高级语言
- 编译型语言执行速度快,不依赖语言环境运行,跨平台差
- 解释型跨平台好,一份代码,到处使用,缺点是执行速度慢,依赖解释器运行
三、Shell 的定义
1、Shell 的含义
首先Shell的英文含义是“壳”; 它是相对于内核来说的,因为它是建立在内核的基础上,面向于用户的一种表现形式,比如我们看到一个球,见到的是它的壳,而非核。 Linux中的Shell,是指一个面向用户的命令接口,表现形式就是一个可以由用户录入的界面,这个界面也可以反馈运行信息;
2、Shell 在Linux中的存在形式
由于Linux不同于Windows,Linux是内核与界面分离的,它可以脱离图形界面而单独运行,同样也可以在内核的基础上运行图形化的桌面。 这样,在Linux系统中,就出现了两种Shell表现形式,一种是在无图形界面下的终端运行环境下的Shell,另一种是桌面上运行的类似Windows 的MS-DOS运行窗口,前者我们一般习惯性地简称为终端,后者一般直接称为Shell
3、Shell 如何执行用户的指令
1、Shell有两种执行指令的方式,
- 第一种方法是用户事先编写一个sh脚本文件,内含Shell脚本,而后使用Shell程序执行该脚本,这种方式,我们习惯称为Shell编程。
- 第二种形式,则是用户直接在Shell界面上执行Shell命令,由于Shell界面的关系,大家都习惯一行行的书写,很少写出成套的程序来一起执行,所以也称命令行。
总结
- Shell 只是为用户与机器之间搭建成的一个桥梁,让我们能够通过Shell来对计算机进行操作和交互,从而达到让计算机为我们服务的目的。
四、Shell 的分类
Linux中默认的Shell是/bin/bash,流行的Shell有ash、bash、ksh、csh、zsh等,不同的Shell都有自己的特点以及用途。 1、bash
- 大多数Linux系统默认使用的Shell,bash Shell是Bourne Shell 的一个免费版本,它是最早的Unix Shell,bash还有一个特点,可以通过help命令来查看帮助。包含的功能几乎可以涵盖Shell所具有的功能,所以一般的Shell脚本都会指定它为执行路径。
2、csh
- C Shell 使用的是“类C”语法,csh是具有C语言风格的一种Shell,其内部命令有52个,较为庞大。目前使用的并不多,已经被/bin/tcsh所取代。
3、ksh
- Korn Shell 的语法与Bourne Shell相同,同时具备了C Shell的易用特点。许多安装脚本都使用ksh,ksh 有42条内部命令,与bash相比有一定的限制性。
4、tcsh
- tcsh是csh的增强版,与C Shell完全兼容。
5、sh
- 是一个快捷方式,已经被/bin/bash所取代。
6、nologin
- 指用户不能登录
7、zsh
- 目前Linux里最庞大的一种 zsh。它有84个内部命令,使用起来也比较复杂。一般情况下,不会使用该Shell。
五、Shell 能做什么
自动化批量系统初始化程序 (update,软件安装,时区设置,安全策略…)
自动化批量软件部署程序 (LAMP,LNMP,Tomcat,LVS,Nginx)
应用管理程序 (KVM,集群管理扩容,MySQL,DELLR720批量RAID)
日志分析处理程序(PV, UV, 200, !200, top 100, grep/awk)
自动化备份恢复程序(MySQL完全备份/增量 + Crond)
自动化管理程序(批量远程修改密码,软件升级,配置更新)
自动化信息采集及监控程序(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL)
配合Zabbix信息采集(收集系统/应用状态信息,CPU,Mem,Disk,Net,TCP Status,Apache,MySQL)
自动化扩容(增加云主机——>业务上线)
zabbix监控CPU 80%+|-50% Python API AWS/EC2(增加/删除云主机) + Shell Script(业务上线)
俄罗斯方块,打印三角形,打印圣诞树,打印五角星,运行小火车,坦克大战,排序算法实现
Shell可以做任何事(一切取决于业务需求)
六、bash 的初始化
1、bash 环境变量文件的加载
1、/etc/profile
- 全局(公有)配置,不管是哪个用户,登录时都会读取该文件。
2、/ect/bashrc
- Ubuntu 没有此文件,与之对应的是 /ect/bash.bashrc
- 它也是全局(公有)的
- bash 执行时,不管是何种方式,都会读取此文件。
3、~/.profile
- 若 bash 是以 login 方式执行时,读取 ~/.bash_profile,若它不存在,则读取
/.bash_login,若前两者不存在,读取/.profile。 - 图形模式登录时,此文件将被读取,即使存在 ~/.bash_profile 和 ~/.bash_login。
4、~/.bash_login
- 若 bash 是以 login 方式执行时,读取 ~/.bash_profile,若它不存在,则读取 ~/.bash_login,若前两者不存在,读取 ~/.profile。
5、~/.bash_profile
- Unbutu 默认没有此文件,可新建。
- 只有 bash 是以 login 形式执行时,才会读取此文件。通常该配置文件还会配置成去读取 ~/.bashrc。
6、~/.bashrc
- 当 bash 是以 non-login 形式执行时,读取此文件。若是以 login 形式执行,则不会读取此文件。
7、~/.bash_logout
- 注销时,且是 longin 形式,此文件才会读取。在文本模式注销时,此文件会被读取,图形模式注销时,此文件不会被读取。
2、bash 环境变量加载
图形模式登录时,顺序读取:/etc/profile 和 ~/.profile
图形模式登录后,打开终端时,顺序读取:/etc/bash.bashrc 和 ~/.bashrc
文本模式登录时,顺序读取:/etc/bash.bashrc,/etc/profile 和 ~/.bash_profile
从其它用户 su 到该用户,则分两种情况:
如果带 -l 参数(或-参数,–login 参数),如:su -l username,则 bash 是 login 的,它将顺序读取以下配置文件:/etc/bash.bashrc,/etc/profile 和~/.bash_profile。
如果没有带 -l 参数,则 bash 是 non-login 的,它将顺序读取:/etc/bash.bashrc 和 ~/.bashrc
注销时,或退出 su 登录的用户,如果是 longin 方式,那么 bash 会读取:~/.bash_logout
执行自定义的 Shell 文件时,若使用 bash -l a.sh 的方式,则 bash 会读取行:/etc/profile 和~/.bash_profile,若使用其它方式,如:bash a.sh,./a.sh,sh a.sh(这个不属于bash Shell),则不会读取上面的任何文件。
上面的例子凡是读取到 ~/.bash_profile 的,若该文件不存在,则读取 ~/.bash_login,若前两者不存在,读取 ~/.profile。
七、bash 特性
1、命令和文件自动补齐
- 很多命令都会提供一个 bash-complete 的脚本,在执行该命令时,敲 tab 可以自动补全参数,会极大提高生产效率。
- linux命令自动补全需要安装 bash-completion
| |
注意: 重启系统后可正常 tab 补齐
默认情况下,Bash 为 Linux 用户提供了下列标准补全功能。
变量补全
用户名补全
主机名补全
路径补全
文件名补全
2、命令历史记忆功能
- Bash 有自动记录命令的功能,自动记录到.bash_history隐藏文件中。还可以在下次需要是直接调用历史记录中的命令
- centos 可以通过/etc/profile中的文件来定义一些参数、
- 在bash中,使用history 命令来查看和操作之前的命令,以此来提高工作效率。
- history是bash的内部命令,所以可以使用 help history命令调出history命令的帮助文档。
- 调用命令的方法:
| |
3、 别名功能
alias命令,别名的好处是可以把本来很长的指令简化缩写,来提高工作效率。
| |
如果想要文件永久生效,只需将上述别名命令写到对应用户或者系统 bashrc 文件中 如果想用真实命令可以在命令前面添加反斜杠 ,使别名失效
| |
4、快捷键
| 快捷 | 作用键 |
|---|---|
| ctrl+A | 把光标移动到命令行开头。如果我们输入的命令过长,想要把光标移动到命令行开头时使用。 |
| ctrl+E | 把光标移动到命令行结尾。 |
| ctrl+C | 强制终止当前的命令。 |
| ctrl+L | 清屏,相当于clear命令。 |
| ctrl+U | 删除或剪切光标之前的命令。我输入了一行很长的命令,不用使用退格键一个一个字符的删除,使用这个快捷键会更加方便 |
| ctrl+K | 删除或剪切光标之后的内容。 |
| ctrl+Y | 粘贴ctrl+U或ctul+K剪切的内容。 |
| ctrl+R | 在历史命令中搜索,按下ctrl+R之后,就会出现搜索界面,只要输入搜索内容,就会从历史命令中搜索。 |
| ctrl+D | 退出当前终端。 |
| ctrl+Z | 暂停,并放入后台。这个快捷键牵扯工作管理的内容,我们在系统管理章节详细介绍。 |
| ctrl+S | 暂停屏幕输出。 |
| ctrl+Q | 恢复屏幕输出。 |
5、前后台作业控制
Linux bash Shell单一终端界面下,经常需要管理或同时完成多个作业,如一边执行编译,一边实现数据备份,以及执行SQL查询等其他的任务。所有的上述的这些工作可以在一个 bash 内实现,在同一个终端窗口完成。
1、前后台作业的定义
- 前后台作业实际上对应的也就是前后台进程,因此也就有对应的 pid。在这里统称为作业。
- 无论是前台作业还是后台作业,两者都来自当前的Shell,是当前Shell的子程序。
- 前台作业:可以由用户参与交互及控制的作业我们称之为前台作业。
- 后台作业:在内存可以自运行的作业,用户无法参与交互以及使用[ctrl]+c来终止,只能通过bg或fg来调用该作业。
2、几个常用的作业命令
command & 直接让作业进入后台运行
[ctrl]+z 将当前作业切换到后台
jobs 查看后台作业状态
fg %n 让后台运行的作业n切换到前台来
bg %n 让指定的作业n在后台运行
kill %n 移除指定的作业n
“n” 为jobs命令查看到的job编号,不是进程id。
每一个job会有一个对应的job编号,编号在当前的终端从1开始分配。
job 编号的使用样式为[n],后面可能会跟有 “+” 号或者 “-” 号,或者什么也不跟。
“+” 号表示最近的一个job,
“-” 号表示倒数第二个被执行的Job。
注,"+" 号与 “-” 号会随着作业的完成或添加而动态发生变化。
通过jobs方式来管理作业,当前终端的作业在其他终端不可见。
3、演示后台作业命令
| |
4、作业脱机管理
- 将作业(进程)切换到后台可以避免由于误操作如[ctrl]+c等导致的job被异常中断的情形,而脱机管理主要是针 对终端异常断开的情形。
- 通常使用nohup命令来使得脱机或注销之后,Job依旧可以继续运行。也就是说nohup忽略所有挂断(SIGHUP) 信号。
- 如果该方式命令之后未指定&符号,则job位于前台,指定&符号,则job位于后台。
| |
5、screen 命令使用
1、简介
Screen 是一款由GNU计划开发的用于命令行终端切换的自由软件。用户可以通过该软件同时连接多个本地或远程的命令行会话,并在其间自由切换。GNU Screen可以看作是窗口管理器的命令行界面版本。它提供了统一的管理多个会话的界面和相应的功能。
1、会话恢复
- 只要Screen本身没有终止,在其内部运行的会话都可以恢复。这一点对于远程登录的用户特别有用——即使网络连接中断,用户也不会失去对已经打开的命令行会话的控制。只要再次登录到主机上执行screen -r就可以恢复会话的运行。同样在暂时离开的时候,也可以执行分离命令detach,在保证里面的程序正常运行的情况下让Screen挂起(切换到后台)。这一点和图形界面下的VNC很相似。
2、多窗口
- 在Screen环境下,所有的会话都独立的运行,并拥有各自的编号、输入、输出和窗口缓存。用户可以通过快捷键在不同的窗口下切换,并可以自由的重定向各个窗口的输入和输出。Screen实现了基本的文本操作,如复制粘贴等;还提供了类似滚动条的功能,可以查看窗口状况的历史记录。窗口还可以被分区和命名,还可以监视后台窗口的活动。 会话共享 Screen可以让一个或多个用户从不同终端多次登录一个会话,并共享会话的所有特性(比如可以看到完全相同的输出)。它同时提供了窗口访问权限的机制,可以对窗口进行密码保护。
2、安装 screen
流行的Linux发行版(例如Red Hat Enterprise Linux)通常会自带screen实用程序,如果没有的话,可以从GNU screen的官方网站下载。
| |
3、语法
| |
4、常用screen参数
| |
5、在 Session下,使用ctrl+a(C-a)
| |
6、常用操作
1、创建会话(-m 强制)
| |
2、关闭会话
| |
3、查看所有会话
| |
4、进入会话
| |
6、清除dead 会话
- 如果由于某种原因其中一个会话死掉了(例如人为杀掉该会话),这时screen -list会显示该会话为dead状态。使用screen -wipe命令清除该会话:
7、关闭或杀死窗口
- 正常情况下,当你退出一个窗口中最后一个程序(通常是bash)后,这个窗口就关闭了。另一个关闭窗口的方法是使用C-a k,这个快捷键杀死当前的窗口,同时也将杀死这个窗口中正在运行的进程。
- 如果一个Screen会话中最后一个窗口被关闭了,那么整个Screen会话也就退出了,screen进程会被终止。
- 除了依次退出/杀死当前Screen会话中所有窗口这种方法之外,还可以使用快捷键C-a :,然后输入quit命令退出Screen会话。需要注意的是,这样退出会杀死所有窗口并退出其中运行的所有程序。其实C-a :这个快捷键允许用户直接输入的命令有很多,包括分屏可以输入split等,这也是实现Screen功能的一个途径,不过个人认为还是快捷键比较方便些。
6、输入输出重定向
一般情况下,计算机从键盘读取用户输入的数据,然后再把数据拿到程序(C语言程序、Shell 脚本程序等)中使用;这就是标准的输入方向,也就是从键盘到程序。 程序中产生数据直接呈现到显示器上,这就是标准的输出方向,也就是从程序到显示器。输入输出方向就是数据的流动方向:
- 输入方向就是数据从哪里流向程序。数据默认从键盘流向程序,如果改变了它的方向,数据就从其它地方流入,这就是输入重定向。
- 输出方向就是数据从程序流向哪里。数据默认从程序流向显示器,如果改变了它的方向,数据就流向其它地方,这就是输出重定向。
1、硬件设备和文件描述符
- 计算机的硬件设备有很多,常见的输入设备有键盘、鼠标等,输出设备有显示器、投影仪、打印机等。不过,在 Linux中,标准输入设备指的是键盘,标准输出设备指的是显示器。
- Linux 中一切皆文件,包括标准输入设备(键盘)和标准输出设备(显示器)在内的所有计算机硬件都是文件。
- 为了表示和区分已经打开的文件,Linux 会给每个文件分配一个 ID,这个 ID 就是一个整数,被称为文件描述符(File Descriptor)。
| 文件描述符 | 文件名 | 类型 | 硬件 |
|---|---|---|---|
| 0 | stdin | 标准输入文件 | 键盘 |
| 1 | stdout | 标准输出文件 | 显示器 |
| 2 | stderr | 标准错误输出文件 | 显示器 |
- Linux 程序在执行任何形式的 I/O 操作时,都是在读取或者写入一个文件描述符。一个文件描述符只是一个和打开的文件相关联的整数,它的背后可能是一个硬盘上的普通文件、FIFO、管道、终端、键盘、显示器,甚至是一个网络连接。
- stdin、stdout、stderr 默认都是打开的,在重定向的过程中,0、1、2 这三个文件描述符可以直接使用。
2、Shell 输出重定向
- 输出重定向是指命令的结果不再输出到显示器上,而是输出到其它地方,一般是文件中。这样做的最大好处就是把命令的结果保存起来,当我们需要的时候可以随时查询。Bash 支持的输出重定向符号如下表所示。
| 类 型 | 符 号 | 作 用 |
|---|---|---|
| 标准输出重定向 | command >file | 以覆盖的方式,把 command 的正确输出结果输出到 file 文件中。 |
| command»file | 以追加的方式,把 command 的正确输出结果输出到 file 文件中。 | |
| 标准错误输出重定向 | command 2>file | 以覆盖的方式,把 command 的错误信息输出到 file 文件中。 |
| command2»file | 以追加的方式,把 command 的错误信息输出到file 文件中。 | |
| 正确输出和错误信息同时保存 | command >file 2>&1 | 以覆盖的方式,把正确输出和错误信息同时保存到同一个文件(file)中。 |
| command»file 2>&1 | 以追加的方式,把正确输出和错误信息同时保存到同一个文件(file)中。 | |
| command>file12>file2 | 以覆盖的方式,把正确的输出结果输出到 file1 文件中,把错误信息输出到 file2 文件中。 | |
| command»file12»file2 | 以追加的方式,把正确的输出结果输出到 file1 文件中,把错误信息输出到 file2 文件中。 | |
| command>file 2>file | 【不推荐】这两种写法会导致 file 被打开两次,引起资源竞争,所以 stdout 和 stderr 会互相覆盖, | |
| command»file2»file |
- 注意: 输出重定向中,> 代表的是覆盖,» 代表的是追加。
- 输出重定向的完整写法其实是 fd>file 或者 fd»file ,其中 fd 表示文件描述符,如果不写,默认为 1,也就是标准输出文件。
- 当文件描述符为 1 时,一般都省略不写,如上表所示;当然,如果你愿意,也可以将 command >file 写作command 1>file,但这样做是多此一举。
- 当文件描述符为大于 1 的值时,比如 2,就必须写上。
- 需要重点说明的是,fd 和 >之间不能有空格,否则 Shell 会解析失败;> 和 file 之间的空格可有可无。为了保持一致,习惯在 > 两边都不加空格。
下面的语句是一个反面教材:
| |
注意 1 和 > 之间的空格。echo 命令的输出结果是 c.biancheng.net,初衷是将输出结果重定向到 log.txt,打开log.txt 文件后,发现文件的内容为 c.biancheng.net 1,这就是多余的空格导致的解析错误。也就是说,Shell 将该条语句理解成了下面的形式:
| |

